Quand on parle de performance système, les ingénieurs se tournent souvent vers des métriques familières :
"Combien de requêtes par seconde peut-il gérer ?"
Mais cette question, bien que courante, manque l'essentiel.
La vraie performance système ne se résume pas à un seul chiffre. Il s'agit de comprendre comment HTTP a évolué, comment les différentes métriques sont liées, et lesquelles guident réellement les décisions techniques.
Les métriques qui comptent ne sont pas toujours celles qu'on mesure en premier.
L'évolution HTTP : De 1.0 à 3.0
Comprendre la performance système commence par comprendre l'évolution d'HTTP.
Chaque version a apporté des changements fondamentaux :
- •HTTP/1.0 : Une requête par connexion
- •HTTP/1.1 : Connexions persistantes, pipelining
- •HTTP/2 : Multiplexage, compression des en-têtes
- •HTTP/3 : Protocole QUIC, migration de connexion
Ces changements modifient fondamentalement la façon dont on mesure la performance. Ce qui fonctionnait pour HTTP/1.1 ne s'applique pas à HTTP/3.
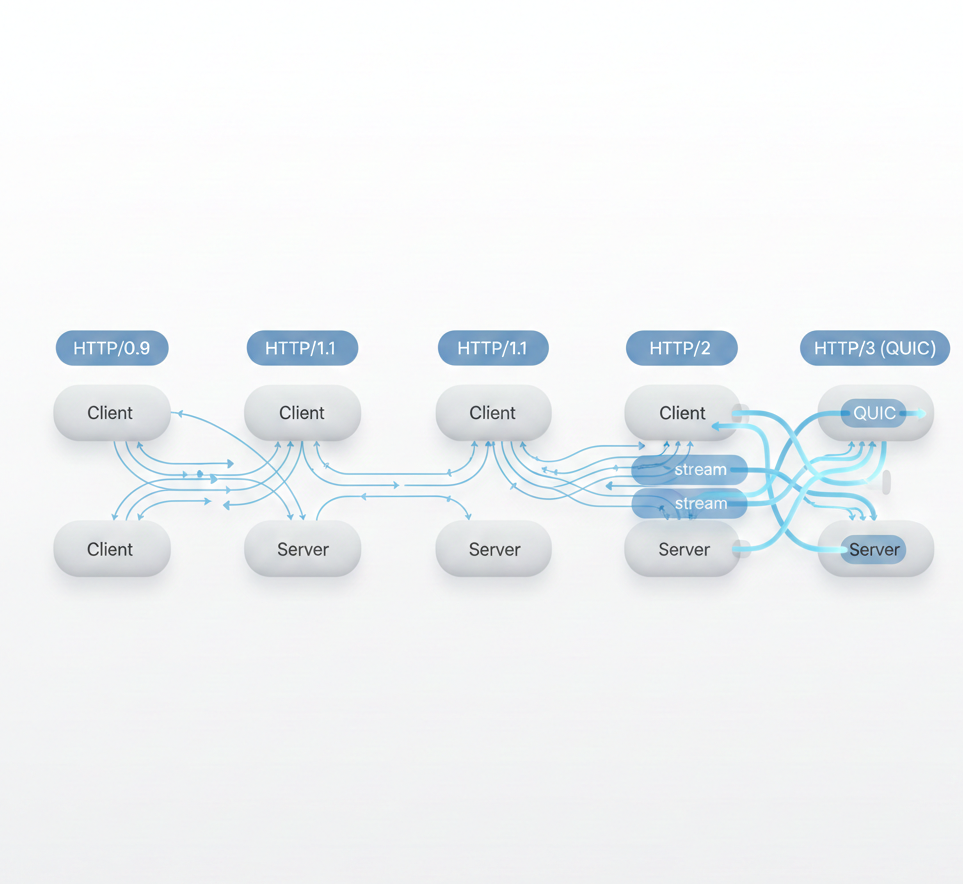
Évolution HTTP : des requêtes séquentielles aux flux multiplexés
QPS : La métrique la plus mal comprise
Les Requêtes Par Seconde (QPS) sont souvent la première métrique vers laquelle les ingénieurs se tournent.
Mais le QPS seul ne vous dit presque rien sur l'état du système :
- ⚠1000 QPS avec 5ms de temps de réponse est très différent de 1000 QPS avec 500ms
- ⚠Le QPS ne révèle pas les patterns de concurrence
- ⚠Le QPS peut masquer l'épuisement des ressources
La vraie question n'est pas "Combien de QPS ?" mais plutôt :
- →Quel est le QPS à des temps de réponse acceptables ?
- →Comment le QPS change-t-il sous charge ?
- →Quel est le ratio QPS-ressources ?

QPS sans contexte : même nombre, états système très différents
TPS : Quand la logique métier compte
Les Transactions Par Seconde (TPS) sont plus proches de la réalité métier que le QPS.
Une transaction peut impliquer :
- •plusieurs requêtes base de données
- •des appels API externes
- •des opérations de cache
- •des interactions avec des files d'attente
Le TPS vous donne une meilleure idée de :
- ✓le débit métier réel
- ✓la capacité système bout-en-bout
- ✓les attentes de charge réalistes
Transaction : une opération métier, plusieurs interactions système
Concurrence : La dimension cachée
La concurrence est là où se cachent la plupart des problèmes de performance.
Deux systèmes peuvent avoir des QPS identiques mais des patterns de concurrence très différents :
Système A :
1000 QPS, 10 connexions concurrentes, 10ms de temps de réponse
Système B :
1000 QPS, 1000 connexions concurrentes, 1000ms de temps de réponse
Même QPS. Comportement système complètement différent.
La concurrence révèle :
- →les patterns de contention des ressources
- →l'efficacité des pools de connexions
- →les emplacements des goulots d'étranglement

Même QPS, concurrence différente : la dimension cachée de la performance
Temps de réponse : La réalité utilisateur
Le temps de réponse est la métrique que les utilisateurs expérimentent réellement.
Mais les distributions de temps de réponse comptent plus que les moyennes :
- ✓P50 : expérience médiane
- ✓P95 : 95% des utilisateurs
- ✓P99 : scénarios du pire cas
Un système avec 50ms de moyenne mais 2000ms en P99 est cassé, même si la moyenne semble bonne.
Les percentiles révèlent ce que les moyennes cachent.
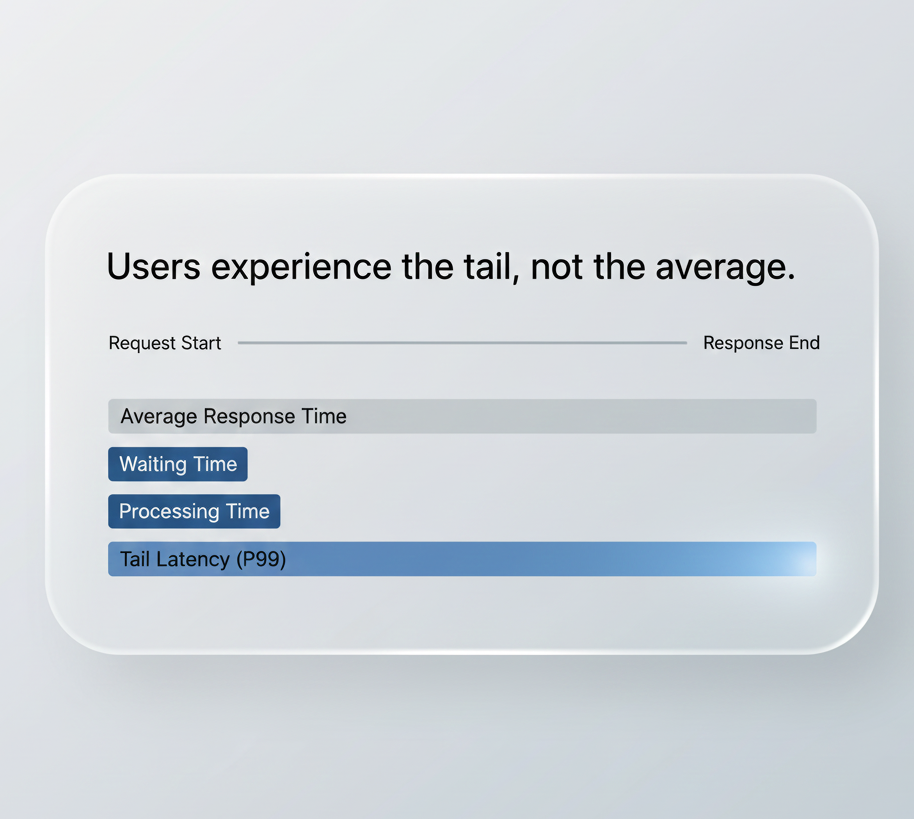
Percentiles de temps de réponse : la distribution raconte la vraie histoire
La relation entre les métriques
Ces métriques n'existent pas isolément. Elles sont connectées :
QPS = Concurrence / Temps de réponse moyenCette relation signifie :
- •améliorer le temps de réponse augmente la capacité QPS
- •augmenter la concurrence nécessite de gérer le temps de réponse
- •optimiser une métrique affecte toutes les autres
On ne peut pas optimiser les métriques indépendamment. Elles forment un système.
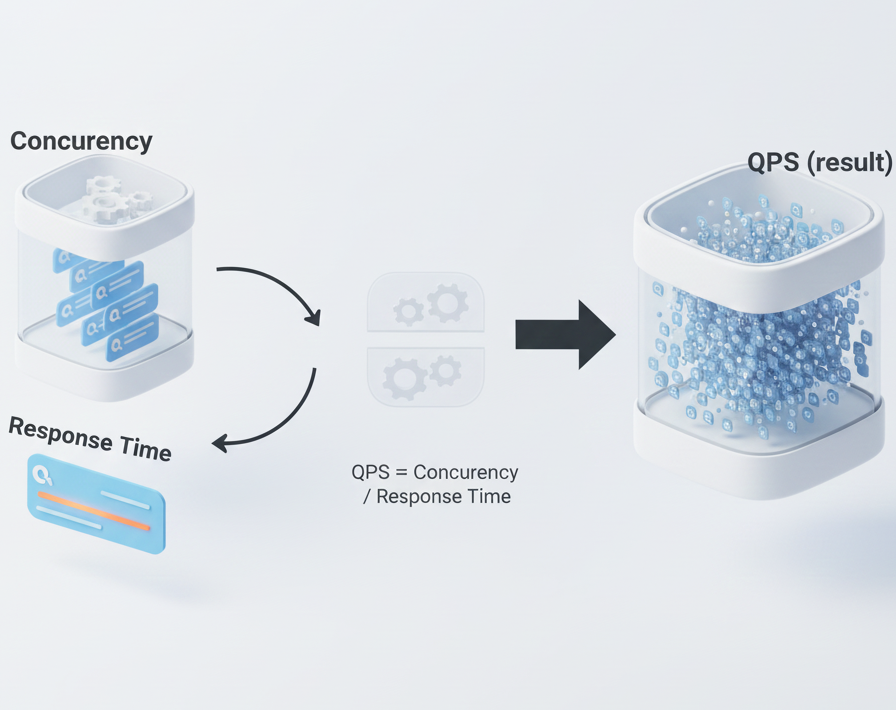
QPS = Concurrence / Temps de réponse : la relation fondamentale
Un exemple pratique : Configuration Nginx
Considérons une configuration de reverse proxy Nginx :
Le paramètre worker_connections impacte directement la concurrence. Mais il est sans signification sans comprendre :
- →les temps de réponse en amont
- →les patterns de requêtes
- →l'efficacité de la réutilisation des connexions
Ajuster worker_connections sans contexte, c'est deviner.
Les décisions de configuration nécessitent de comprendre l'image complète des métriques.
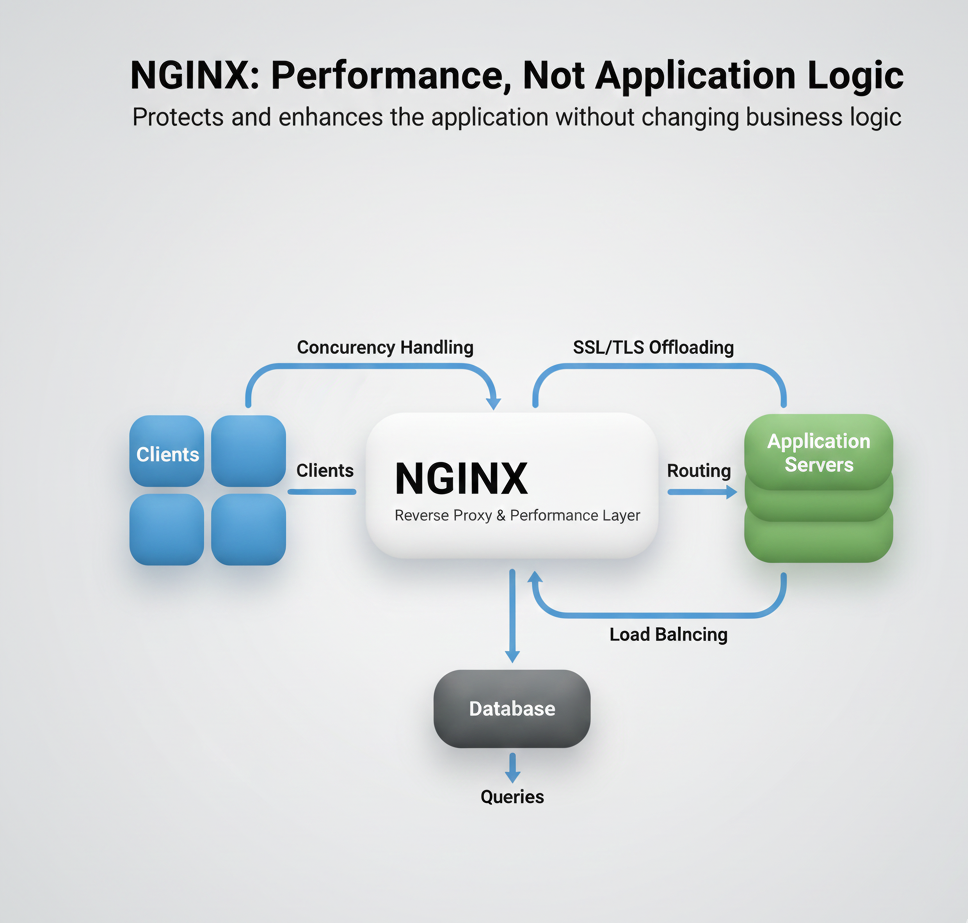
Architecture Nginx : comment worker_connections se rapporte à la concurrence, QPS et temps de réponse
Conclusion
La performance système ne consiste pas à trouver la métrique parfaite unique.
Il s'agit de comprendre comment HTTP a évolué, comment les métriques sont liées, et quelles combinaisons guident réellement les décisions techniques.
Les métriques qui comptent :
Avant d'optimiser un seul chiffre, il faut comprendre :
- →les relations entre les métriques
- →quelles métriques comptent pour votre cas d'usage
- →comment l'évolution HTTP change les règles
Comprendre les métriques — et le système suit.
Écrit par
Youssef Laidouni
Ingénieur Full Stack | Java • Angular • PHP | APIs, MVP, Performance & Automatisation